
一、Kafka 采取了分片和索引机制,将每个partition分为多个segment,每个segment对应2个文件 log 和 index
index文件中并没有为每一条message建立索引,采用了稀疏存储的方式 每隔一定字节的数据建立一条索引,避免了索引文件占用过多的空间和资源,从而可以将索引文件保留到内存中 缺点是没有建立索引的数据在查询的过程中需要小范围内的顺序扫描操作。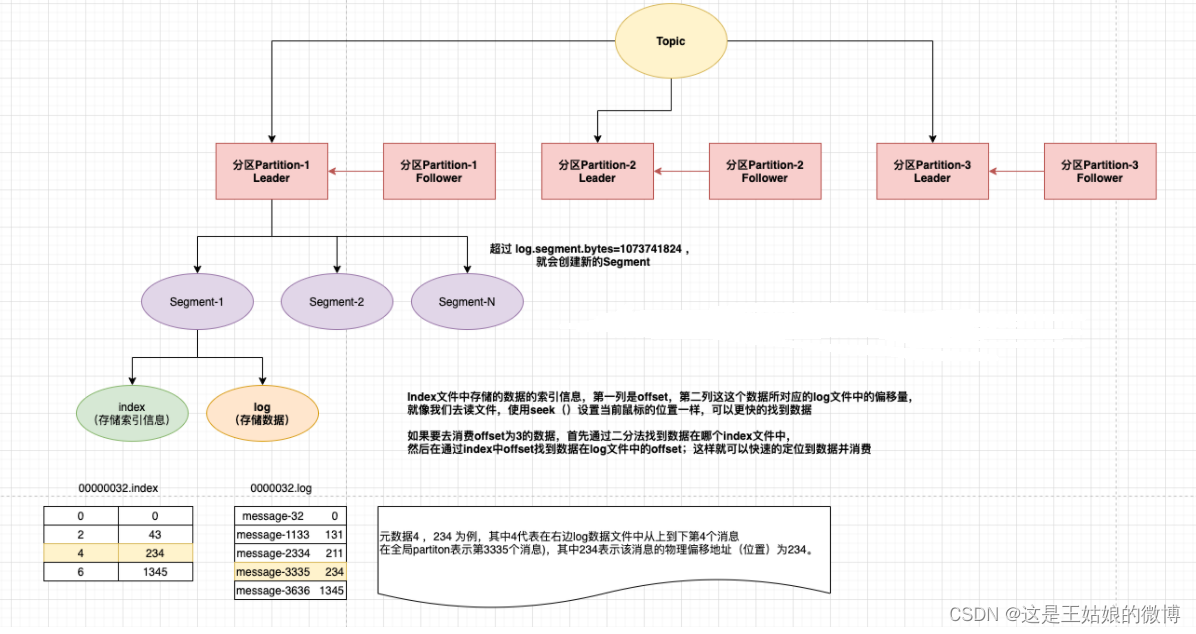
二、segment的创建时机是什么时候?
/bin/server.properties
# The maximum size of a log segment file. When this size is reached a new log segment will be created. 默认是1G,当log数据文件大于1g后,会创建一个新的log文件(即segment,包括index和log) log.segment.bytes=1073741824
#分段一 初始进来阶段 00000000000000000000.index 00000000000000000000.log #分段二 数字 1234指的是当前文件的最小偏移量offset,即上个文件的最后一个消息的offset+1 00000000000000001234.index 00000000000000001234.log #分段三 00000000000000088888.index 00000000000000088888.log